
När man installerar ett nytt system behöver man fylla det med data från antingen ett gammalt system eller data som har sammanställts för att importeras. Denna process kallas datamigrering och innebär att data flyttas från en digital lagringsplats till en annan. Datamigreringar kan ske flera gånger under en applikations livstid.
En datamigrering skiljer sig från en integration genom att den är en engångsprocess, medan integrationer sker löpande för att kontinuerligt synkronisera data mellan system.
Detta är en process som ofta glöms bort eller underskattas i projekt. Trots detta utgör den ofta en relativt stor del av ett digitaliseringsprojekt.
Datamigreringen kan variera beroende på vilket system data kommer ifrån och vart den ska flyttas. Även om verktygen som används, typen och mängden av data kan skilja sig åt, följer processen oftast samma grundläggande steg.
Import / Export
Det är viktigt att förstå vilken data som är aktuell och hur den fungerar. Processen börjar med att säkerställa ett sätt att extrahera data från källsystemet så att den kan bearbetas. Många program har inbyggda funktioner för att exportera data till CSV-filer. CSV står för Comma Separated Values och är ett standardiserat format för att lagra data. CSV-filer är läsbara textfiler som är lätta att inspektera eller importera till kalkylprogram som Excel, Google Sheets eller Numbers.
Andra program har specialbyggda import/export-verktyg som kan ansluta till systemet och exportera data till CSV. Ett annat alternativ är att ansluta direkt till applikationens databas för att exportera data, vilket kan kräva experimenterande och problemlösning.
Samtidigt behöver man undersöka hur man kan importera data till målsystemet. Precis som med dataexport finns det många olika metoder för detta. Många gånger finns det en importfunktion som kan läsa CSV-filer och skapa motsvarande data i applikationen. Här är det viktigt att använda rätt format på CSV-filen. Ofta erbjuds exempel- eller mallfiler av systemets leverantör.
Vissa system har specialbyggda importverktyg som erbjuder många möjligheter att anpassa importen efter specifika behov. Ibland kan man importera data direkt till applikationens databas, men det är viktigt att vara försiktig eftersom databasen kan skadas om man skriver till den direkt utan att använda avsedda API:er eller metoder.
Skapa en karta för att hitta rätt
I större projekt är data ofta strukturerad i flera olika tabeller med inbyggda relationer. Det är därför viktigt att skapa en karta över hur datan ser ut i källsystemet och hur den ska se ut i målsystemet.
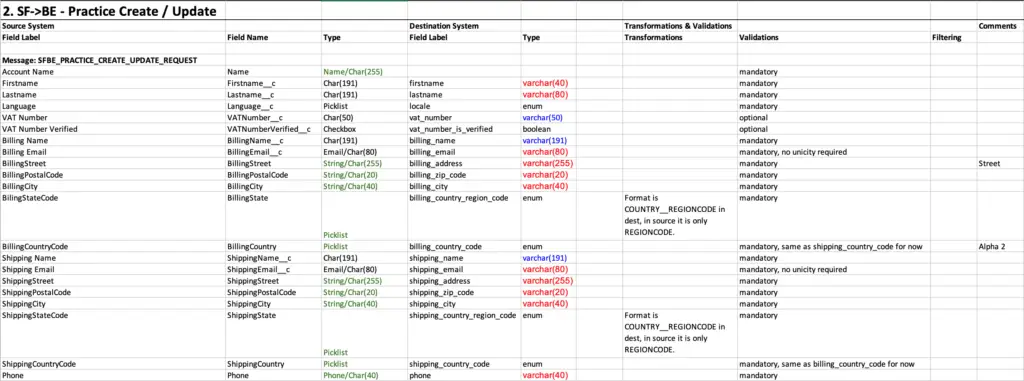
Ett effektivt sätt är att skapa ett kartläggningsdokument där data från källsystemet listas, en tabell åt gången, tillsammans med alla fält. Det är också bra att dokumentera information om fälten, såsom:
-
- Datatyp (tal, strängar, datum, etc.)
-
- Format och längder på datan
-
- Alternativ som kan väljas i rullgardinsfält (drop-down)
-
- Om fältet är valfritt eller obligatoriskt
-
- Nyckelfält
Med källdatan dokumenterad kopplar man ihop den med motsvarande tabeller och fält i målsystemet. Även här behöver information om fälten samlas in. Detta gör det tydligt om det finns några problem som behöver hanteras, såsom omformatering av data eller brist på data.
Ett bra dokument visar inte bara problem utan gör det också tydligt i vilken ordning data ska importeras. Ett kartläggningsdokument går att granska och diskutera i en grupp.
Förbered data för migrering
När kartan är klar kan data förberedas för migrering. Ett vanligt sätt är att läsa in CSV-filer i Excel och där städa och omvandla data till önskat format. Det är bra att inte ändra data direkt i CSV-filen, utan att använda formler för att omvandla data generellt. Detta gör processen upprepbar med ny data. Det innebär att migreringen kan förberedas och att data som ska migreras kan uppdateras från nyexporterade CSV-filer allteftersom projektet fortlöper.
Vid arbete med relaterade tabeller är detta tillvägagångssätt också fördelaktigt, eftersom nycklar skapas när datan importeras. I en förälder-till-barn-relation måste förälderdatan först skapas och dess nyckel genereras i systemet. Barndatan behöver därefter uppdateras med korrekt nyckel till sin förälder innan den kan importeras.
Vi nämner här “Excel”, men vilket kalkylarksprogram som helst kan användas. Ibland blir datamängderna väldigt stora och filerna kan behöva delas upp för att underlätta arbetet. Kalkylarksprogram tenderar att bli långsamma med många rader och fält.
Målet är att transformera datan från den gamla strukturen till en ny struktur anpassad för målsystemet. Under denna process är det också bra att städa sin data. Städning kan innebära att dubblettinformation raderas och att fält får vettiga värden. Säkerställ att data- och integritetspolicys upprätthålls.
Om information saknas i obligatoriska fält i målsystemet behöver den skapas här. I vissa fall kan värdet “beräknas” eller hämtas från ett externt system, eller så kan ett standardvärde sättas i fältet där data saknas.
Läs in data
När källdatan är förberedd kan man läsa in den i målsystemet. Om man har tillgång till ett testsystem eller en sandlåda är detta ett utmärkt ställe att testa migreringen. Det blir sällan helt rätt första gången, särskilt när större mängder data hanteras. Importverktyget kan ge felmeddelanden eller så kan resultatet bli felaktigt.
Här behöver man felsöka, rätta till sina importfiler och ibland också kartläggningsdokumentet. Sedan försöker man igen.

Validera
När datan är i systemet behöver man kontrollera att allt har blivit rätt. Att kontrollera all data är väldigt tidskrävande och många gånger överflödigt, men det finns några saker som är särskilt viktiga att granska.
-
- Antal rader: Är antalet rader samma i käll- och målsystemet? Om inte, kan du förklara varför? Avvikelser tyder ofta på att något har gått fel och att någon rad har haft ett fel.
-
- Stickprov: Stickprov är ett bra sätt att generellt se att data har migrerats korrekt. Bestäm hur många stickprov som behövs och hur de ska spridas över datamängden. Det kan till exempel vara viktigare att ta stickprov på nyare data än på äldre data.
-
- Datumfält: Datumfält kan vara extra problematiska. Datum kan vara formaterade på olika sätt i olika system och i olika delar av världen. Tidszoner kan påverka resultatet av migreringen. Detta bör ha identifierats redan i kartläggningen, men det är viktigt att kontrollera att det har blivit rätt.
-
- Textfält: Text kan bestå av olika teckenuppsättningar. Specialtecken, som å, ä och ö, representeras digitalt på olika sätt. Många äldre system använder teckenuppsättningen ISO medan nyare ofta använder UTF-8. Om detta inte hanteras korrekt kan specialtecken bli konstiga.
Nu borde din data vara migrerad och redo att användas i det nya systemet.
Avancerade metoder
Det finns många varianter av denna process.
Det går att automatisera migreringen, exempelvis med hjälp av ett ETL-verktyg. Då kan man successivt utveckla och testa sin migrering mot en utvecklingsmiljö. På detta sätt kan man göra en snabb och felfri migrering till produktionssystemet när det ska tas i bruk. Detta är ett säkert tillvägagångssätt, men det kräver kunskap och tid. För att migrera en gång är detta ofta onödigt.
På samma sätt som man kan automatisera migreringen, kan man automatisera valideringen. För att göra detta skriver man ofta ett testskript som läser samma data från både käll- och målsystem och kontrollerar att värdena stämmer. Detta kräver extra resurser och blir därför onödigt noggrant, men om man hanterar mycket känslig information kan detta vara en metod att använda.

